Variables indicadoras
Variables cualitativas o categóricas: no tienen una escala natural de medida, son variables discretas. A estas variables se le asigna un conjunto de niveles para tener en cuenta el efecto que pueda tener la variable sobre la respuesta. Esto se hace usando variables indicadoras o también llamadas variables ficticias.
Por lo general, para identificar de forma cuantitativa los niveles de las variables categóricas se asigna el valor de 0 y 1, aunque, se puede asignar dos valores cualesquiera que diferencien las categorías.
Supongamos que en un modelo tenemos dos variables, \(x_1\) y \(x_2\), la variable \(x_1\) es cuantitativa, pero \(x_2\) es una variable categórica que tiene dos estados. La variable \(x_2\) se cambiará por un vector (variable indicadora) de unos y ceros donde el primer estado se asignará el valor de 0 y al segundo estado el valor de 1.
En lugar de que la variable \(x_2\) tenga tres estados, se deben crear dos variables indicadores de unos y ceros, \(x_2\) y \(x_3\).
\(x_2\) |
\(x_3\) |
|
|---|---|---|
0 |
1 |
si la observación indica el primer estado. |
1 |
0 |
si la observación indica el segundo estado. |
0 |
0 |
si la observación indica el tercer estado. |
En general, si una variable categórica o cualitativa tiene \(\alpha\) estados o niveles, se deben crear \(\alpha - 1\) variables indicadoras y cada uno con los valores de 0 y 1.
Cuando los estados o niveles de las variables categóricas no tienen un orden de importancia, no se recomienda asignar valores del 1, 2, 3, 4, etc., porque se estaría indicando que algunos estados o niveles son más importantes que otros. Este tipo de variables categóricas se denominan nominales. Por el contrario, las variables categóricas que pueden ordenarse se denominan ordinales, por ejemplo: una variable que indique el nivel de estudios, primaria, secundaria, pregrado, posgrado, etc.; otro ejemplo sería las variables con escala Likert.
La base de datos con variables indicadores debe cumplir con dos características:
1. Mutuamente excluyentes: una observación solo puede pertenecer a una sola categoría.
2. Exhaustivos: ninguna categoría debe quedar por fuera.
Código en R:
datos = read.csv("Ofertas laborales.csv", sep = ";", dec = ",", header = T)
print(head(datos))
cargo vacantes salario_honorarios sexo
1 contador 3 2200000 indiferente
2 contador 1 2500000 indiferente
3 contador 1 2000000 indiferente
4 analista de mercados 3 1500000 indiferente
5 coodinador de planeacion 1 2200000 indiferente
6 administradora 1 1500000 femenino
nivel_educativo años_experiencia idiomas
1 profesional 5.00 no dato
2 profesional 2.00 no dato
3 profesional 2.00 no dato
4 profesional 1.00 no dato
5 profesional 0.25 no dato
6 profesional 1.00 no dato
str(datos)
'data.frame': 86 obs. of 7 variables:
$ cargo : chr "contador" "contador" "contador" "analista de mercados " ...
$ vacantes : int 3 1 1 3 1 1 1 1 1 1 ...
$ salario_honorarios: int 2200000 2500000 2000000 1500000 2200000 1500000 1500000 2000000 2000000 1500000 ...
$ sexo : chr "indiferente" "indiferente" "indiferente" "indiferente" ...
$ nivel_educativo : chr "profesional" "profesional" "profesional" "profesional" ...
$ años_experiencia : num 5 2 2 1 0.25 1 0.5 2 2 3 ...
$ idiomas : chr "no dato" "no dato" "no dato" "no dato" ...
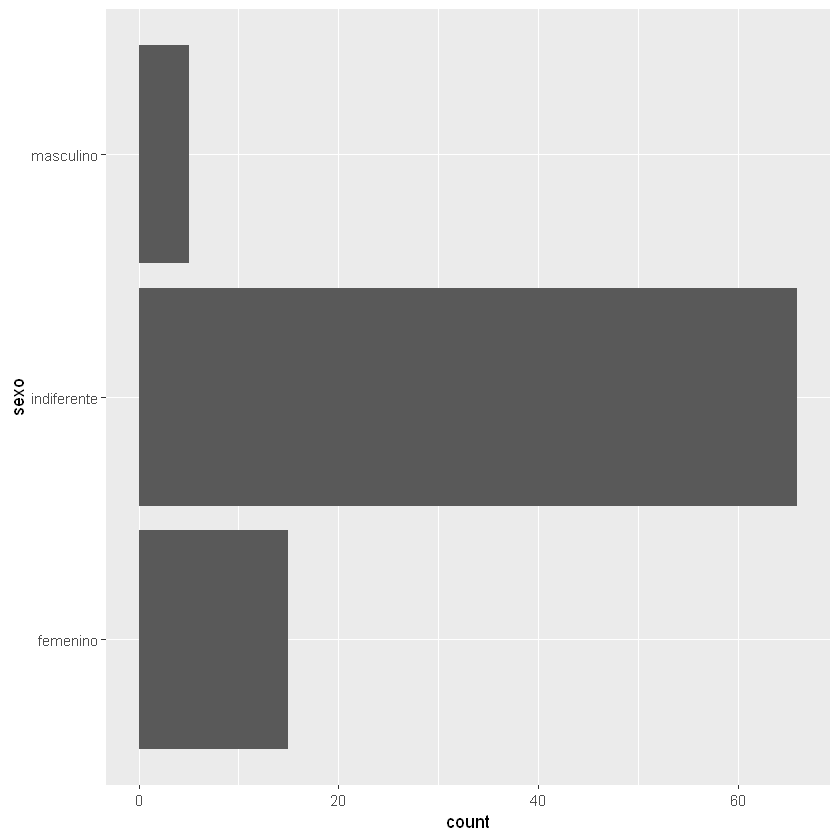
print(table(datos[,c("sexo")]))
femenino indiferente masculino
15 66 5
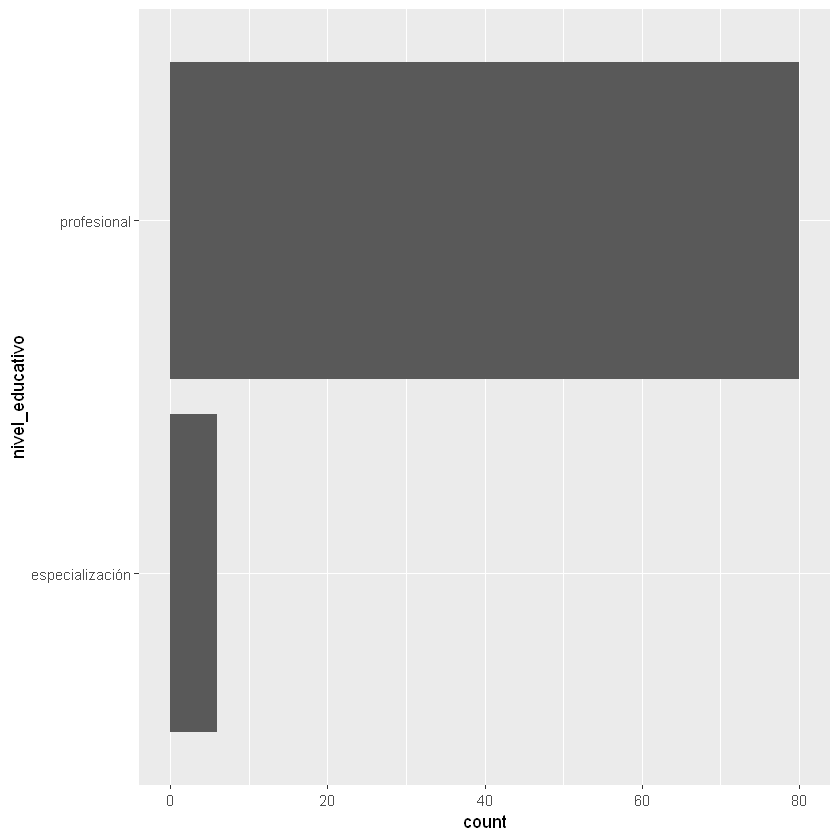
print(table(datos[,c("nivel_educativo")]))
especialización profesional
6 80
library(ggplot2)
ggplot(data = datos) + geom_bar(aes(y = sexo))
ggplot(data = datos) + geom_bar(aes(y = nivel_educativo))
datos$sexo <- factor(datos$sexo,
levels = c(unique(datos$sexo)),
labels = c(1:length(unique(datos$sexo))))
print(datos$sexo)
[1] 1 1 1 1 1 2 2 1 1 3 3 1 1 3 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1
[39] 1 1 1 2 1 2 1 2 1 1 1 2 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 2 2 1 3 1 1 2 1 2 2 2
[77] 1 1 1 2 1 1 1 1 3 1
Levels: 1 2 3
datos$nivel_educativo <- factor(datos$nivel_educativo,
ordered = TRUE,
levels = c("profesional", "especialización"),
labels = c(1:length(unique(datos$nivel_educativo))))
print(datos$nivel_educativo)
[1] 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 2 1 1 1 2 2 1 1
[39] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1
[77] 1 1 1 1 1 1 1 1 1 1
Levels: 1 < 2
print(head(datos))
cargo vacantes salario_honorarios sexo nivel_educativo
1 contador 3 2200000 1 1
2 contador 1 2500000 1 1
3 contador 1 2000000 1 1
4 analista de mercados 3 1500000 1 1
5 coodinador de planeacion 1 2200000 1 1
6 administradora 1 1500000 2 1
años_experiencia idiomas
1 5.00 no dato
2 2.00 no dato
3 2.00 no dato
4 1.00 no dato
5 0.25 no dato
6 1.00 no dato