Regresión Logística para clasificación
La regresión logística se utiliza muchas veces como herramienta de clasificación; sin embargo, cabe señalar que la capacidad de clasificar o discriminar entre los dos niveles de la variable respuesta se debe más al grado de separación entre los niveles y al tamaño de los coeficientes de regresión que al propio modelo logístico.
Hay dos herramientas de clasificación que se utilizan con la regresión logística:
Curva ROC (Receiver Operating Characteristics).
Matriz de confusión.
Cada una de estas herramientas se basan en un punto de corte. El punto de corte es la probabilidad óptima con que se separan las observaciones en 1 y 0. Así se analizan las predicciones acertadas y las no acertadas.
Los modelos de regresión logística pueden hacer una buena clasificación y no siempre son modelos bien ajustados. Si el interés es estrictamente la clasificación, no es tan importante el ajuste del modelo. Asimismo, un modelo logístico bien ajustado puede no diferenciar claramente los dos niveles de la variable respuesta.
Curva ROC:
La curva ROC se usa para examinar el equilibrio entre la detección de verdaderos positivos y evitar los falsos positivos. La curva se define con la proporción de verdaderos positivos en el eje vertical y la proporción de faltos positivos en el eje horizontal.
Punto de corte: para clasificar las predicciones en \(1\) y \(0\) se debe definir un punto de corte, este es la probabilidad que debemos definir y las predicciones iguales o mayores que esta probabilidad las etiquetaremos como \(1\) y las predicciones con probabilidades menores como \(0\). Por ejemplo, si definimos el punto de corte como 0,70, las observaciones con probabilidades mayores o iguales que 0,50 será la categoría \(1\) y las demás observaciones serán \(0\).
Después de definir el punto de corte y de realizar la clasificación, la matriz de confusión nos mostrará las observaciones que fueron bien clasificadas y las que se les asignó una clasificación incorrecta.
Los puntos que comprende la curva ROC indican la tasa de verdaderos positivos en diferentes umbrales de falsos positivos. Para crear la curva, las predicciones de la clasificación se ordenan según la probabilidad estimada del modelo para la clase positiva, con los valores grandes primero. Comenzando en el origen, el impacto de cada predicción en la tasa de verdaderos positivos y la tasa de falsos positivos dará como resultado una curva que se traza verticalmente (para una predicción correcta) u horizontal (para una predicción incorrecta).
La línea diagonal desde la esquina inferior izquierda hasta la esquina superior derecha del diagrama representa un clasificador sin valor predictivo. Este tipo de clasificador detecta verdaderos positivos y falsos positivos exactamente a la misma velocidad, lo que implica que el clasificador no puede discriminar entre las dos categorías (\(1\) y \(0\)). Esta es la línea de base por la cual se pueden juzgar otros clasificadores. Las curvas ROC que caen cerca de esta línea indican modelos que no son muy útiles.
De manera similar, el clasificador perfecto tiene una curva que pasa por el punto con una tasa de 100 por ciento de verdaderos positivos y 0 por ciento de tasa de falsos positivos. Es capaz de identificar correctamente todos los verdaderos positivos antes de clasificar incorrectamente cualquier resultado negativo.
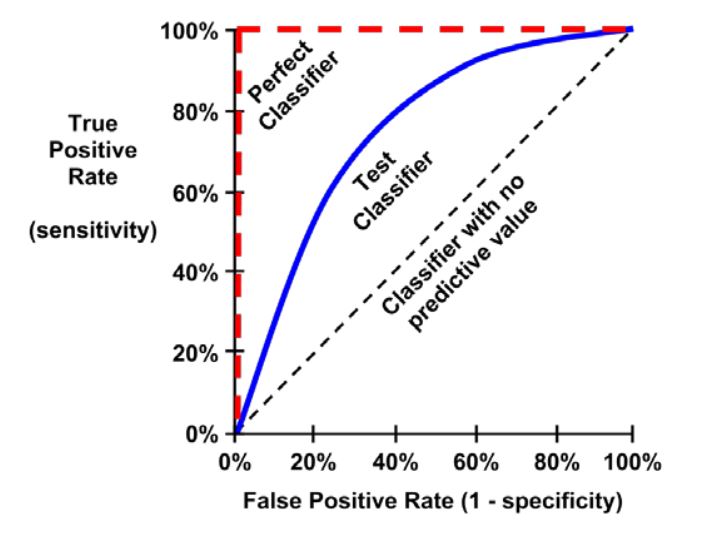
CurvaROC
Sensitivity: es la tasa de los verdaderos positivos.
Specificity: es la tasa de los falsos positivos (1 - Specificity).
Cuanto más cerca esté la curva del clasificador perfecto, mejor será para identificar valores positivos. Esto se puede medir utilizando una estadística conocida como el área bajo la curva ROC - AUC (area under the ROC curve). El AUC mide el área total bajo la curva ROC. AUC varía de 0,5 (para un clasificador sin valor predictivo) a 1,0 (para un clasificador perfecto). Una convención para interpretar las puntuaciones AUC utiliza un sistema similar a las calificaciones académicas con letras:
0.9 – 1.0 = Excelente
0,8 – 0,9 = Bueno
0.7 – 0.8 = Aceptable
0.6 – 0.7 = Pobre
0,5 – 0,6 = Sin discriminación
El área bajo la curva ROC (AUC) es una métrica que evalúa qué tan bien un modelo de regresión logística clasifica los resultados positivos y negativos en todos los límites posibles.
Resulta que el AUC es la probabilidad de que si tomara un par de observaciones al azar, una con \(Y=1\) y otra con \(Y=0\), la observación con \(Y=1\) tiene una probabilidad predicha más alta que la otra. El AUC, por lo tanto, da la probabilidad de que el modelo clasifique correctamente tales pares de observaciones.
También vale la pena señalar que dos curvas ROC pueden tener una forma muy diferente y, sin embargo, tener un AUC idéntico. Por esta razón, AUC puede ser extremadamente engañoso. La mejor práctica es usar AUC en combinación con un examen cualitativo de la curva ROC. De manera similar, el clasificador perfecto tiene una curva que pasa por el punto con una tasa de 100 por ciento de verdaderos positivos y 0 por ciento de tasa de falsos positivos. Es capaz de identificar correctamente todos los verdaderos positivos antes de clasificar incorrectamente cualquier resultado negativo.
Matriz de confusión:
Una matriz de confusión es una tabla que clasifica las predicciones según sí coinciden con el valor real de los datos. Una de las dimensiones de la tabla indica las posibles categorías de valores predichos mientras que la otra dimensión indica lo mismo para los valores reales. Aunque solo vemos matrices de confusión de 2 x 2, se puede crear una matriz para un modelo que predice cualquier número de categorías.
Cuando el valor predicho es el mismo que el valor real, esta es una clasificación correcta. Las predicciones correctas caen en la diagonal de la matriz de confusión. Las celdas de la matriz fuera de la diagonal indican los casos en los que el valor predicho difiere del valor real. Estas son predicciones incorrectas. Las medidas de rendimiento para los modelos de clasificación se basan en los recuentos de predicciones que entran y salen de la diagonal en estas tablas.
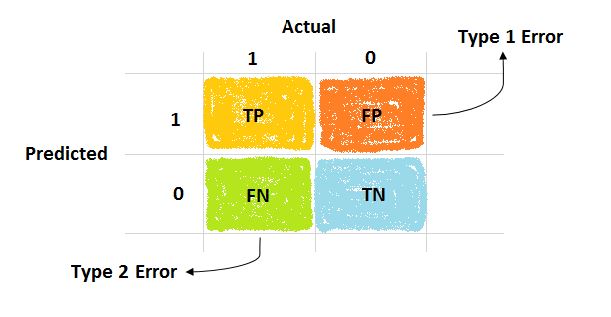
MatrizConfusion
La matriz de confusión tabula las predicciones en cuatro categorías:
Verdadero Positivo - TP (True Positive): clasifica correctamente la categoría \(1\) de la variable de interés.
Verdadero Negativo - TN (True Negative): clasifica correctamente la categoría \(0\) de la variable de interés.
Falso positivo - FP (False Positive): clasifica incorrectamente la categoría \(1\).
Falso negativo - FN (False Negative): clasificia incorrectamente la categoría \(0\).
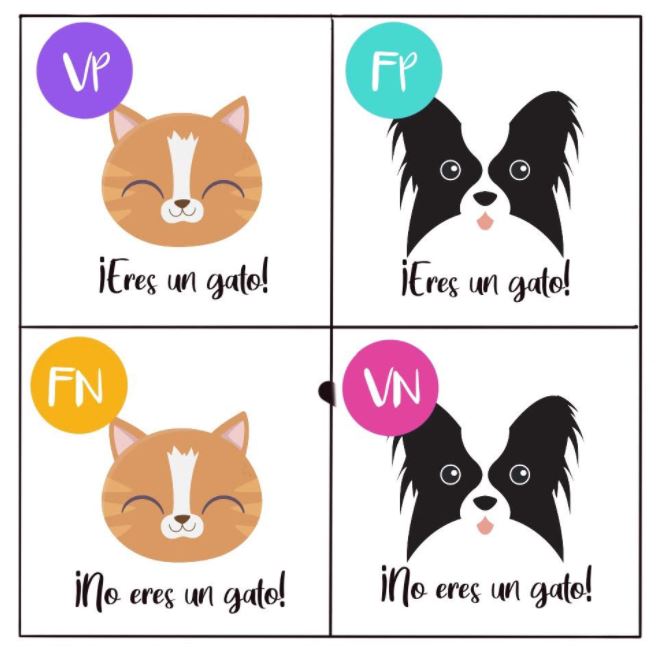
MatrizConfusion2
Métricas:
Con la matriz de confusión podemos calcular las siguientes métricas.
Accuracy:
El accuracy es la proporción que representa el número de verdaderos positivos y verdaderos negativos dividido por el número total de predicciones.
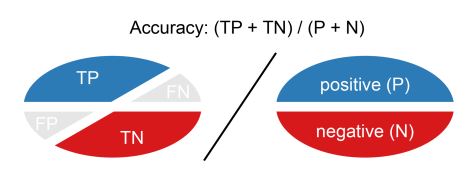
Accuracy
Error Rate:
Lo contrario al accuracy es el error.
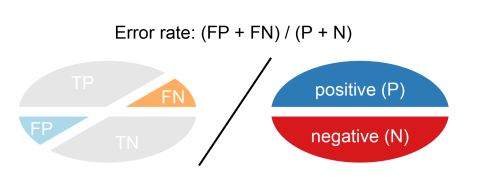
ErrorRate
Sensitivity:
La sensibilidad de un modelo (Sensitivity), también denominada tasa de verdaderos positivos (TP), mide la proporción de observaciones positivas que se clasificaron correctamente. Por lo tanto, como se muestra en la siguiente fórmula, se calcula como el número de verdaderos positivos dividido por el número total de positivos en los datos: los clasificados correctamente (los verdaderos positivos), así como los clasificados incorrectamente (los falsos negativos).
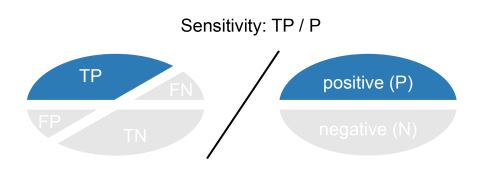
Sensitivity
Specificity:
La especificidad de un modelo (Specificity), también llamada tasa de negativos verdaderos (TN), mide la proporción de observaciones negativas que se clasificaron correctamente. Al igual que con la sensibilidad, esto se calcula como el número de negativos verdaderos dividido por el número total de negativos: los negativos verdaderos más los falsos positivos.
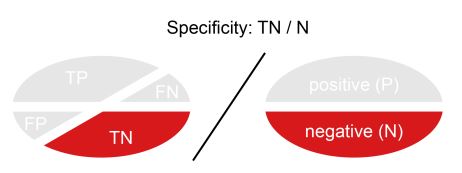
Specificity
Otras dos medidas de desempeño relacionadas con la sensitivity y la specificity son precision y recall.
Precision:
Precision es la proporción de observaciones positivas que son positivo verdadero (TP), en otras palabras, cuando el modelo de clasificación predice la categoría de \(1\), esta métrica indica la frecuencia de estar en lo cierto. Un modelo preciso solo predecirá la categoría positiva \((1)\) en casos muy probables de ser positivos.
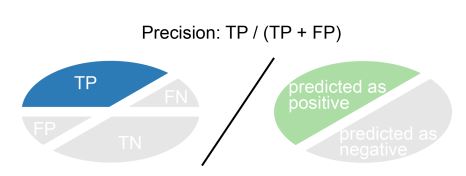
Precision
Recall:
Recall es una medida de qué tan completos son los resultados. Es el número de positivos verdaderos (TP) sobre el total de positivos. Esto es lo mismo que la sensibilidad, pero se podría interpretar diferente. Un modelo con alto recall captura gran parte de las observaciones positivas, lo que significa que tienen una gran amplitud.
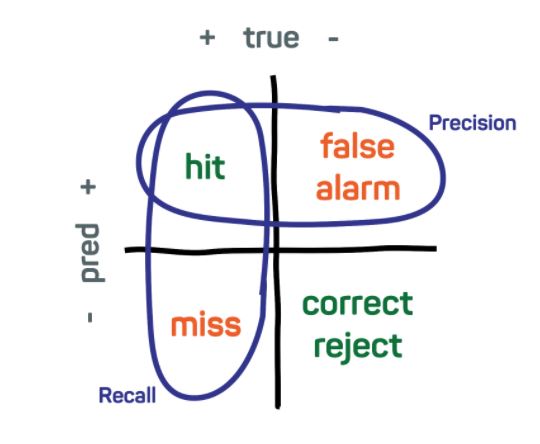
Precision-recall
F-measure:
Una medida del rendimiento del modelo que combina 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 y 𝑟𝑒𝑐𝑎𝑙𝑙 en un solo número se conoce como medida F (F-measure), a veces también llamada puntuación F1 o puntuación F. La medida F combina 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 y 𝑟𝑒𝑐𝑎𝑙𝑙 utilizando la media armónica. Se utiliza la media armónica en lugar de la media aritmética, ya que tanto 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 como 𝑟𝑒𝑐𝑎𝑙𝑙 se expresan como proporciones entre cero y uno.