Teoría K-Means
Se busca agrupar las observaciones semejantes y dividir en grupos que tengan características diferentes. Con la agrupación o clustering los puntos de datos de una muestra grande se agrupan según sus similitudes. Así que la agrupación comprende e identifica patrones ocultos de los datos. Los métodos para agrupar los datos hacen parte de los métodos de aprendizaje no supervisado del Machine Learning.
Aprendizaje no supervisado:
Los modelos que realizan tareas de agrupamiento o Clustering hacen parte de los modelos de aprendizaje automático no supervisado. Estos modelos se aplican a los conjuntos de datos que tienen una etiqueta o clase, es decir, que no tienen una variable \(y\) respuesta. Estos modelos se entrenan sin ningún valor objetivo y solo aprenden de las características inherentes que poseen los datos y los clasifica en uno o más grupos. Con este agrupamiento no se está definiendo ninguna etiqueta de clases, solo se están separando las muestras diferentes entre sí.
K-Means:
Este método agrupa los datos en \(k\) número de grupos o clusters en un espacio de muestra dado. Las similitudes de los datos en un cluster se miden en términos de distancia de los puntos desde el centro de la agrupación. El centro del cluster se conoce como centroide. Generalmente, antes de aplicar este método de asigna el valor de \(k\) y el algoritmo K-Means intenta minimizar la suma de las distancias entre los puntos de datos y el centroide del grupo al que perteneces.
En el agrupamiento de K-Means, cada grupo está representado por su centro (es decir, centroide) que corresponde a la media de los puntos asignados al grupo.
Para medir las distancias de cada punto con su centroide podemos usar la siguiente fórmula:
Donde,
\(P_i\): puntos dentro de un Cluster.
\(C_k\): centroide del Cluster \(k\).
\(n\): cantidad de observaciones.
Pasos para K-Means:
Iniciar el modelo con un número de \(k\) cluters.
Aleatoriamente ubicar los \(k\) centroides entre los puntos de datos.
Calcular los distancias entre todos los puntos de datos con cada centroide y asignar los puntos al centroide más cercano.
Volver a calcular los centroides de los nuevos grupos.
Repetir los pasos 3 y 4 hasta que se cumplan los criterios para parar las iteraciones.
Para terminar y dejar de iterar el modelo se puede aplicar alguno de los siguientes criterios:
Si los nuevos centros de los clusters son iguales a los anteriores.
Si los puntos de datos de los clusters siguen siendo los mismos.
Cuando se alcanza el número máximo de iteraciones. Este criterio lo define el analista.
Ejemplo:
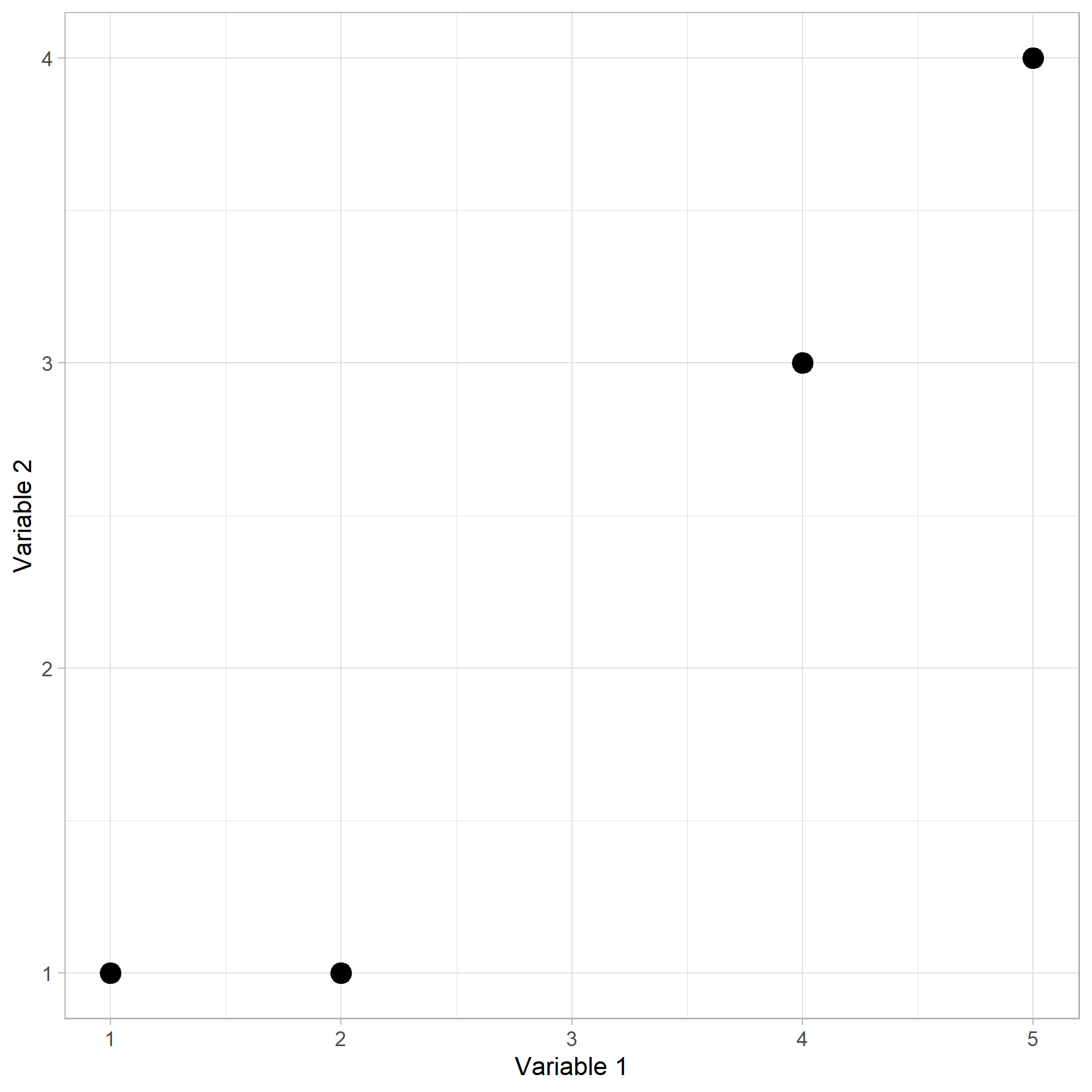
Puntos
La anterior figura se representa por la siguiente matriz:
Tenemos \(n = 4\) individuos u observaciones y cada uno con \(p = 2\) variables.
Solución:
Para \(k=2\) clusters, se inicializarán aleatoriamente. Supongamos que el centroide 1 se ubica en \(C1 = (1,1)\) y el centroide 2 en \(C2 = (2,1)\). La siguiente figura muestra los puntos con los dos centroides.
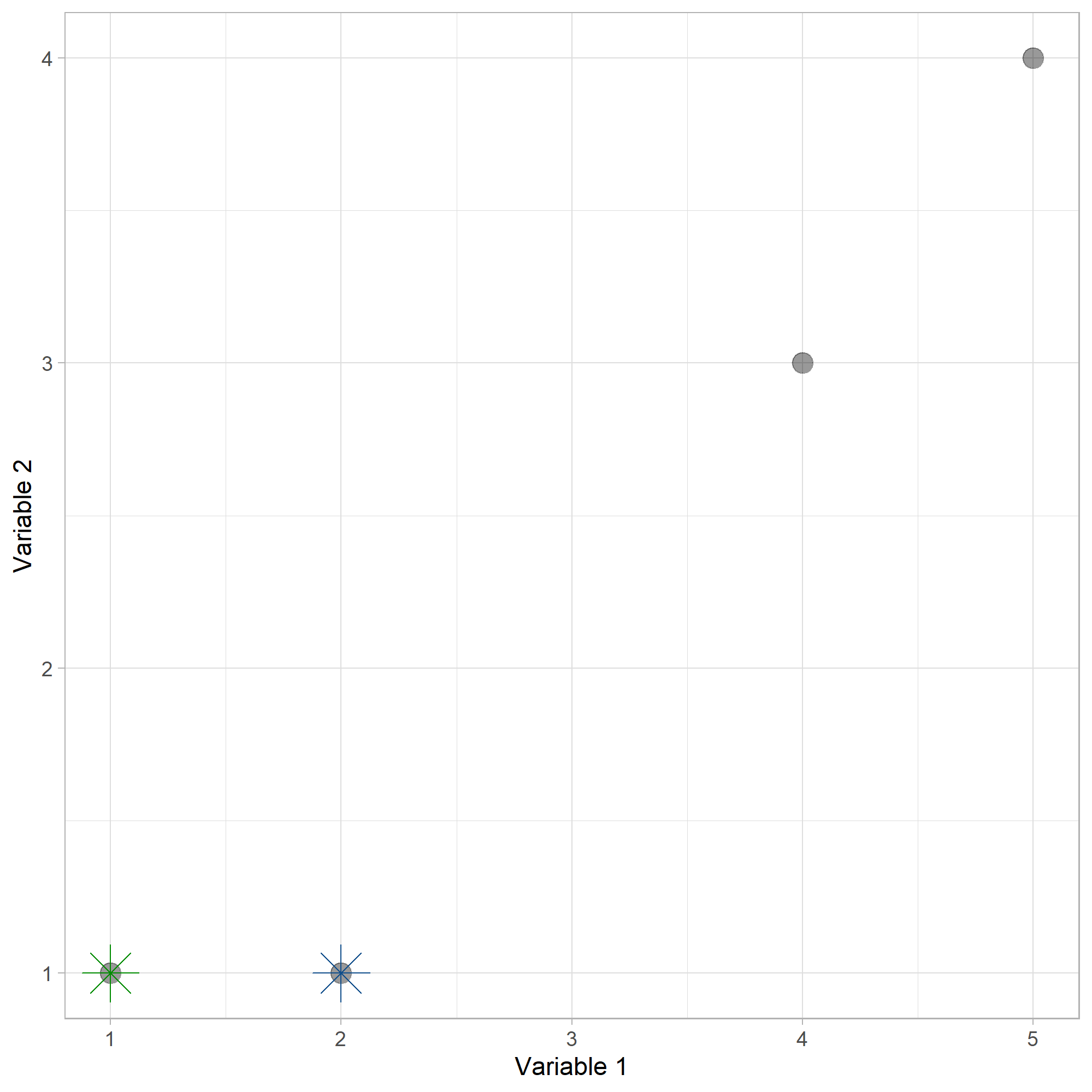
Centroides
Distancias de todos los puntos al centroide 1 - \(C1 = (1,1)\)
\(D1:\sqrt{(1-1)^2+(1-1)^2}=0\)
\(D2:\sqrt{(1-2)^2+(1-1)^2}=1\)
\(D3:\sqrt{(1-4)^2+(1-3)^2}=3,61\)
\(D4:\sqrt{(1-5)^2+(1-4)^2}=5\)
Distancias de todos los puntos al centroide 2 - \(C2 = (2,1)\)
\(D1:\sqrt{(2-1)^2+(1-1)^2}=1\)
\(D2:\sqrt{(2-2)^2+(1-1)^2}=0\)
\(D3:\sqrt{(2-4)^2+(1-3)^2}=2,83\)
\(D4:\sqrt{(2-5)^2+(1-4)^2}=4,24\)
Resumiendo:
Con el criterio de asignar el centroide más cercano a cada punto, solo el punto (1,1) pertenece a C1, los demás puntos pertenecen a C2.
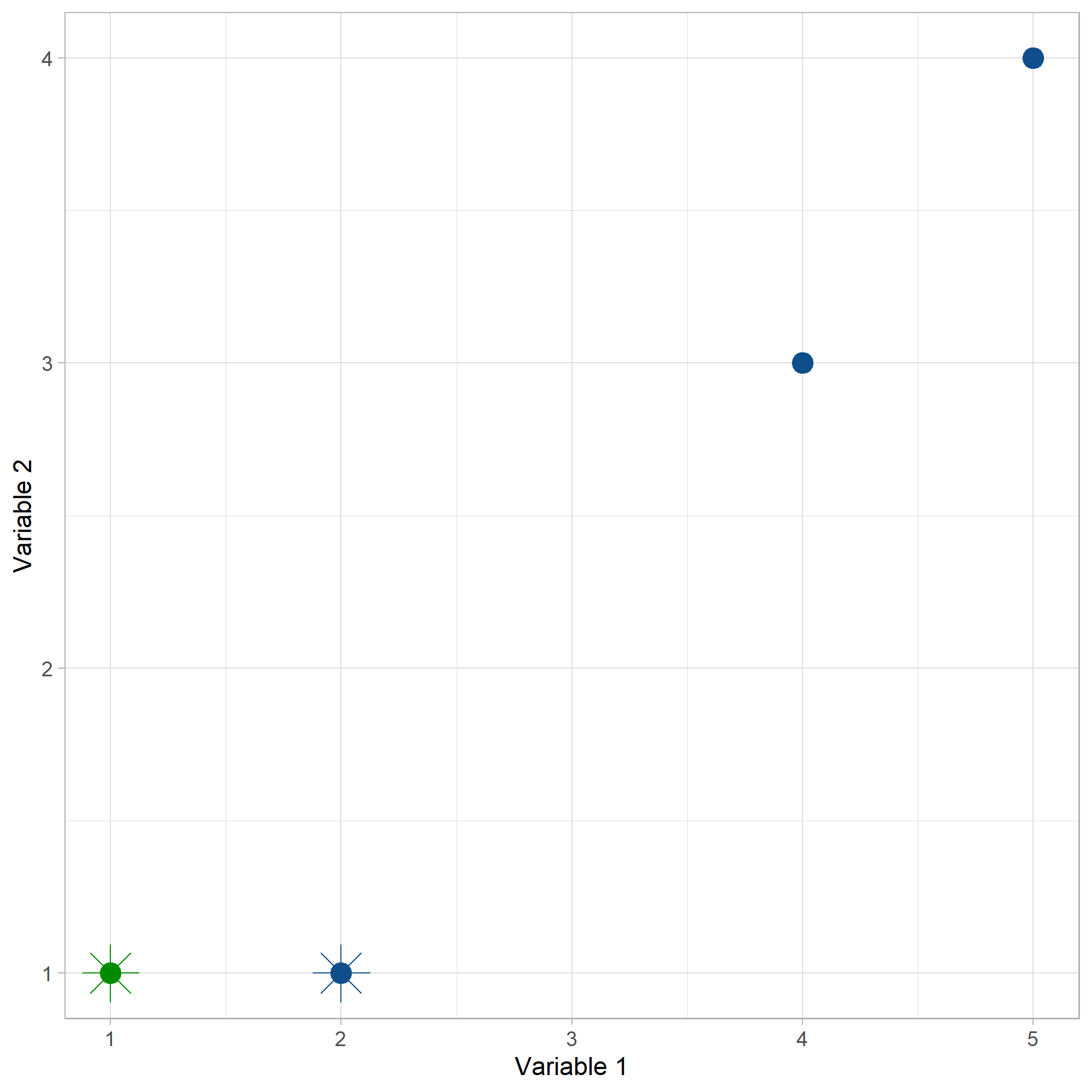
Iteracion1
Luego, se determinan los nuevos centroides. Como el cluster 1 solo tiene un solo individuo, el centroide 1 sigue siendo el mismo. Para el cluster 2, el nuevo centroide se calcula como la media (means) de los puntos así:
Nuevamente, la matriz de distancias sería:
Con el criterio de la mínima distancia al centroide, ahora los puntos (1,1) y (2,1) pertenecen al cluster 1 y los puntos (4,3) t (5,4) pertenecen al cluster 2.
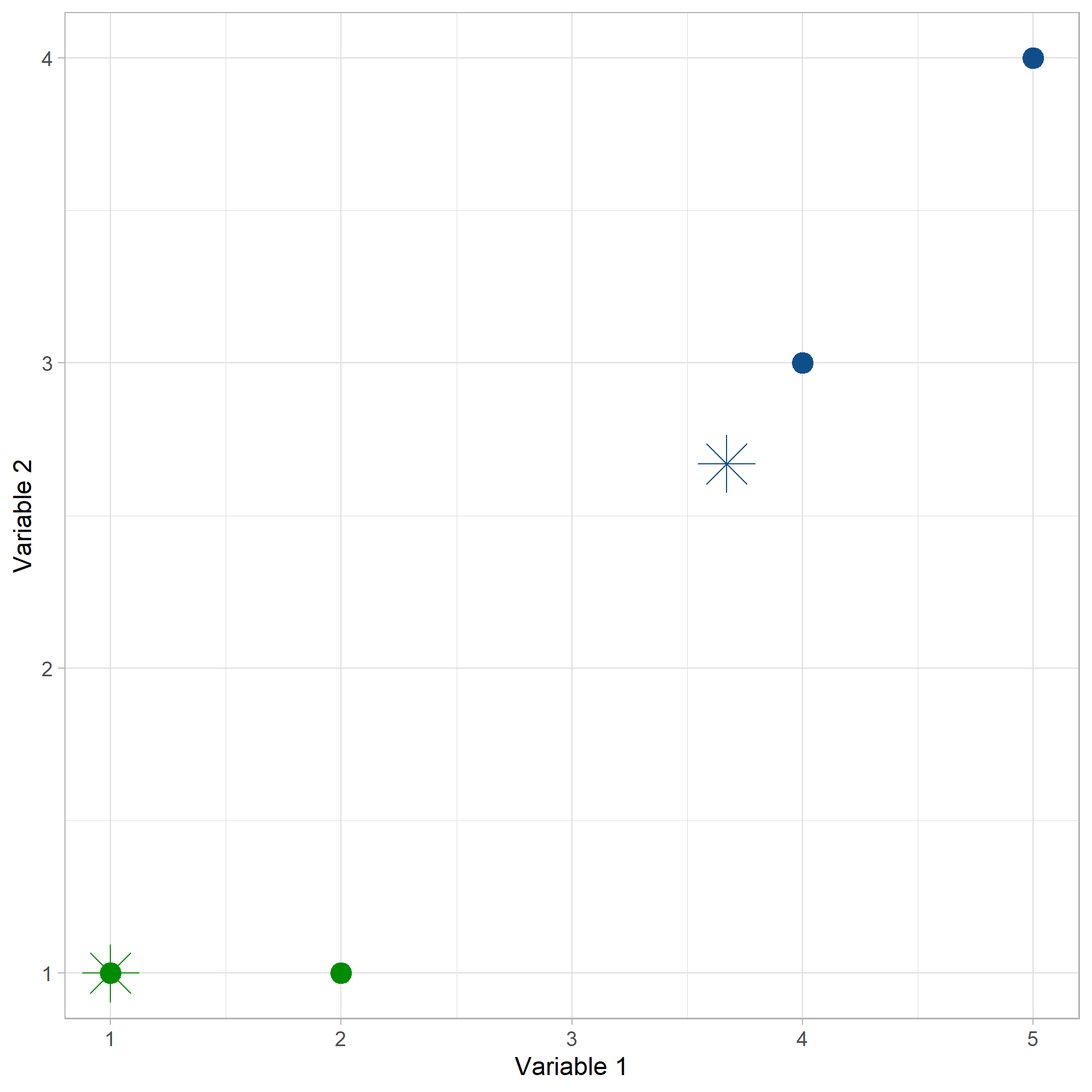
Iteracion2
Los dos nuevos centroides serán:
Para estos nuevos centroides la matriz de distancias es:
Nuevamente con el criterio de distancia mínima a los centroides, los puntos (1,1) y (2,1) siguen perteneciendo al cluster 1 y los puntos (4,3) y (5,4) al cluster 2. Como no hay cambios en los individuos en los clusters, por tanto, el algoritmo K-Means converge en este punto.

Iteracion3
La clasificación queda de la siguiente manera:
Individuos |
Variable 1 |
Variable 2 |
Cluster |
|---|---|---|---|
Individuo 1 |
1 |
1 |
1 |
Individuo 2 |
2 |
1 |
1 |
Individuo 3 |
4 |
3 |
2 |
Individuo 4 |
5 |
4 |
2 |
Distancias:
Veremos las distancias Manhattan, Euclídea y Minkowsky.
Tenemos \(n\) individuos u observaciones y cada uno con \(p\) variables.
Un individuo será el vector: \(x_i = \begin{bmatrix} x_{i1}, & x_{i2}, & x_{i3} & ..., & x_{ip} \end{bmatrix}\)
Distancias Manhattan:
La distancia Manhattan entre el individuo \(x_i\) y el individuo \(x_j\) se calcula con el valor absoluto de la resta entre las filas \(i\) y \(j\). Cada variable del individual \(i\) se resta con las de individuo \(j\), la sumatoria de estas restas en valor absoluto es el cálculo de la distancia Manhattan.
Distancia Euclídea:
Se restan las variables entre los dos individuos y se eleva al cuadrado. La raíz cuadrada de todas estas distancias por variable es la distancia Euclidiana.

Distancias
Distancia Minkowski:
Si \(p = 1\): Distancia Manhattan.
Si \(p = 2\): Distancia Euclídea.

Minkowski
Escalamiento de variables:
Se recomienda estandarizar o normalizar las variables antes de calcular las distancias, especialmente cuando tenemos grandes diferencias en las unidades de las variables.
Número óptimo de clusters:
Se emplean técnicas subjetivas.
Método del codo (Elbow method):
Se corre el algoritmo para diferentes \(k\) clusters, por ejemplo, variando entre 1 y 10.
Para cada cluster calcular el WCSS.
Trazar una curva de WCSS con el número de clusters \(k\).
La ubicación de la curva (codo) se considera como un indicador apropiado para el agrupamiento.
Se implementa la técnica del codo a la suma de las distancias al cuadrado de cada punto de un cluster con respecto a su centroide. El resultado se llama WCSS (Within-Cluster Sum of Square).
El valor máximo de WCSS es cuando solo se hace con un cluster, cuando \(k = 1\).
Donde,
\(P_i\): puntos dentro de un Cluster.
\(C_k\): centroide del Cluster \(k\).
\(n\): cantidad de observaciones.
Método de la silueta (Average silhouette method):
La silueta es una medida de qué tan cerca se compara el elemento con otros elementos dentro del mismo grupo y qué tan suelto es con los elementos de los grupos vecinos. Un valor de silueta cercano a 1 implica que un elemento está el grupo correcto, mientras que un valor de silueta cercano a -1 implica que está en el grupo incorrecto. El método de silueta promedio calcula la silueta promedio de todos los elementos en el conjunto de datos en función de diferentes valores para \(k\). Si la mayoría de los elementos tienen un valor alto, entonces el promedio será alto y la configuración de agrupamiento se considera adecuada. Sin embargo, si muchos puntos tienen un valor de silueta bajo, el promedio también será bajo y la configuración de agrupamiento no es óptima. Similar al método del codo, para usar el método de la silueta promedio, representamos la silueta promedio contra diferentes valores de \(k\). El valor \(k\) correspondiente a la silueta promedio más alta representa el número óptimo de grupos.
Se corre el algoritmo para diferentes \(k\) clusters, por ejemplo, variando entre 1 y 10.
Para cada cluster calcular la silueta promedio de las observaciones.
Trazar una curva de silueta promedio con el número de clusters \(k\). El número óptimo de clusters \(k\) es el que maximiza la silueta promedio sobre un rango de valores posibles para \(k\).
La ubicación de la curva (codo) se considera como un indicador apropiado para el agrupamiento.
Método del gap estadístico (Gap statistic method):
Compara la diferencia entre los grupos creados a partir de los datos observados y los grupos creados a partir de un conjunto de datos generado aleatoriamente, conocido como conjunto de datos de referencia. Para un \(k\) dado, el gag estadístico es la diferencia en el WCSS total para los datos observados y el del conjunto de datos de referencia. El número óptimo de clusters se denota por el valor \(k\) que produce el gap estadístico más grande.
Desventajas del K-Means:
Supone conocimiento previo del conjunto de datos para elegir el número apropiado de clusters \(k\).
El resultado de la clasificación es sensible a la selección aleatoria inicial de centroides. Se pueden obtener diferentes agrupaciones en diferentes ejecuciones del algoritmo.
Es sensible a los valores atípicos.
Si se reorganizan los datos, es posible obtener soluciones diferentes cada vez que cambia el orden de los datos.