Imputación de datos
Los métodos tradicionales de imputación de datos son:
Imputación con la Media.
Imputación por Regresión.
Imputación por Regresión Estocástica.
Se usará la función mice() de la librería mice.
Instalar la librería: install.packages("mice")
Imputación con la Media:
Una solución rápida para los datos que faltan es reemplazarlos por la media de los datos de cada variable.
imp_data_mean <- mice(data, method = "mean", m = 1, maxit = 1, print = FALSE)
Con el argumento method = "mean" se especifica la imputación con la
media. El argumento m = 1 para indicar que no es imputación
múltiple, solo es un conjunto de datos. Con maxit = 1 se establece
el número de iteraciones como 1 que es sin iteraciones.
Con print = FALSE se evita que vaya imprimiendo en consola los
resultados que va realizando.
La imputación con la media es una solución rápida y se recomienda usarla sólo cuando faltan pocos datos. Con esta imputación se subestima la varianza y se altera las correlaciones entre las variables
Imputación por Regresión:
Incorpora el conocimiento de otras variables con la idea de producir imputaciones. Se hace un ajuste de regresión lineal con los datos observados y con las predicciones de los datos faltantes del modelo ajustado se hace la imputación.
En la función mice() el método de regresión lineal se llama
"norm.predict" y se agrega en el argumento method =.
imp_data_regre <- mice(data, method = "norm.predict", m = 1, maxit = 1, print = FALSE)
Con imputación por regresión se producen estimaciones no sesgadas de las medias; sin embargo, las correlaciones aumentarán y disminuirá la variabilidad de los datos. La subestimación de la varianza de los datos dependerá de la varianza explicada y de cantidad de datos faltantes.
Imputación por Regresión Estocástica:
Realiza un ajuste de regresión lineal, pero agrega ruido a las predicciones. Primero calcula los coeficientes del modelo de regresión y de la varianza de los errores, luego calcula el valor pronosticado para cada dato faltante y agrega un valor aleatorio (ruido) del residual a la predicción.
Se agrega el argumento method = "norm.nob".
imp_data_stoch <- mice(data, method = "norm.nob", m = 1, maxit = 1, print = FALSE)
Con la imputación por regresión estocástica se podría conservar la correlación entre las variables.
Aplicación de imputación de datos:
Base de datos:
datos <- read.csv("EAM_2019.csv", sep = ";", dec = ",", header = T)
print(head(datos))
ï..ciiu personal_mujer personal_hombre gasto_personal gasto_financiero
1 1051 36 140 9352991 3240559
2 1030 40 176 7334998 1468298
3 3290 15 172 6668544 1547666
4 3091 88 373 22088759 35203208
5 3290 18 53 5219070 2861773
6 3290 18 53 5219070 2861773
costos_gastos_produccion gastos_adm_ventas inversion_AF ventas
1 6846304 22920307 4979745 192609248
2 5941761 12310286 5615593 115741258
3 6996020 2564695 773444 44580029
4 4175751 171278876 10501572 162509864
5 11037978 13691919 6423171 87324374
6 11037978 13691919 6423171 87324374
Con una base de datos conocida generaremos aleatoriamente unos datos
faltantes. Se realizará con la función ampute() de la librería
mice. La base de datos nueva con los datos faltantes se extraer con
$amp.
library(mice)
Warning message:
"package 'mice' was built under R version 4.1.3"
Attaching package: 'mice'
The following object is masked from 'package:stats':
filter
The following objects are masked from 'package:base':
cbind, rbind
df <- datos[, c("gasto_personal", "gasto_financiero")]
df <- ampute(df)$amp
Supongamos que la base de datos es de tres variables: las primeras dos
tienen datos faltantes y la última no tiene este problema. La última
variable serán las ventas.
df$ventas <- datos[, "ventas"]
print(head(df, 10)) # En las primeras filas se pueden ver los NAs.
gasto_personal gasto_financiero ventas
1 9352991 3240559 192609248
2 NA 1468298 115741258
3 6668544 1547666 44580029
4 22088759 NA 162509864
5 NA 2861773 87324374
6 5219070 NA 87324374
7 NA 647945 33370073
8 4756263 630568 59514053
9 NA 20390274 26727389
10 NA 542136 57342249
Cantidad de NAs:
print(sum(is.na(df)))
[1] 210
Cantidad de NAs por columna:
print(colSums(is.na(df)))
gasto_personal gasto_financiero ventas
113 97 0
Visualización de los NAs:
install.packages("VIM")
library(VIM)
Warning message:
"package 'VIM' was built under R version 4.1.3"
Loading required package: colorspace
Loading required package: grid
VIM is ready to use.
Suggestions and bug-reports can be submitted at: https://github.com/statistikat/VIM/issues
Attaching package: 'VIM'
The following object is masked from 'package:datasets':
sleep
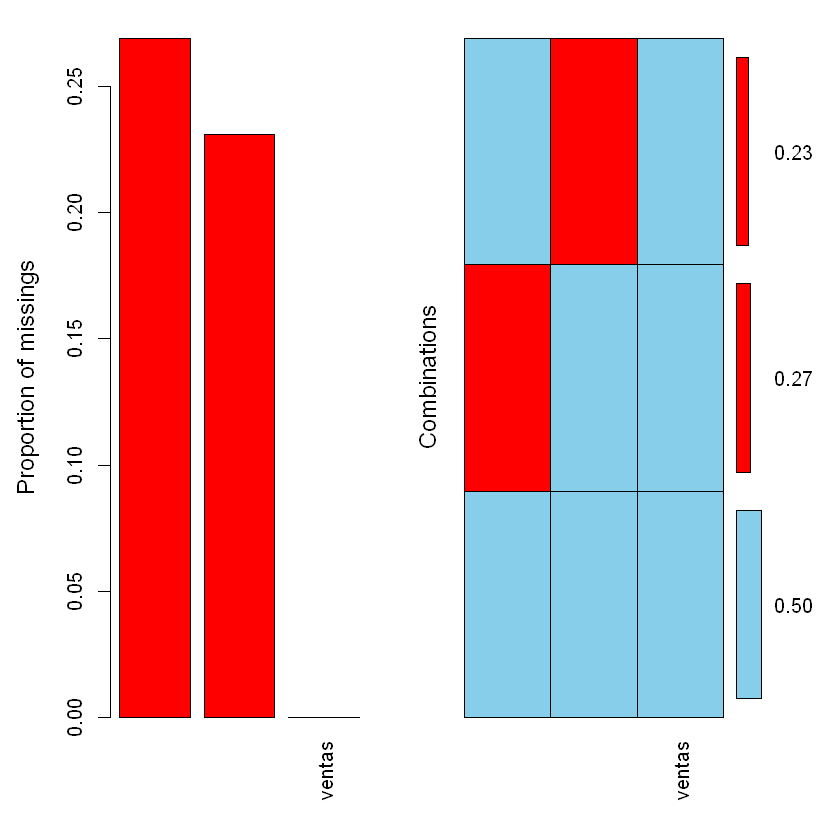
aggr(df,numbers=T,sortVar=T)
Variables sorted by number of missings:
Variable Count
gasto_personal 0.2690476
gasto_financiero 0.2309524
ventas 0.0000000
Imputación con la media:
imp_data_mean <- mice(df[, c("gasto_personal", "gasto_financiero")], method = "mean", m = 1, maxit = 1, print = FALSE)
El valor medio imputado a cada variable se extrae con:
imp_data$imp$gasto_personalimp_data$imp$gasto_financiero
print(head(imp_data_mean$imp$gasto_personal))
1
2 18203281
5 18203281
7 18203281
9 18203281
10 18203281
13 18203281
print(head(imp_data_mean$imp$gasto_financiero))
1
4 2482088
6 2482088
11 2482088
14 2482088
24 2482088
29 2482088
Estos dos valores medios también los podemos calcular con la función de
la base de R llamada mean(), pero debemos agregar el argumento
na.rm = TRUE para que realice el cálculo omitiendo los valores
NA.
print(mean(df[, "gasto_personal"], na.rm = TRUE))
[1] 18203281
print(mean(df[, "gasto_financiero"], na.rm = TRUE))
[1] 2482088
Usamos la función mice() porque realiza el cálculo de imputación y
crea la columna con los datos imputados.
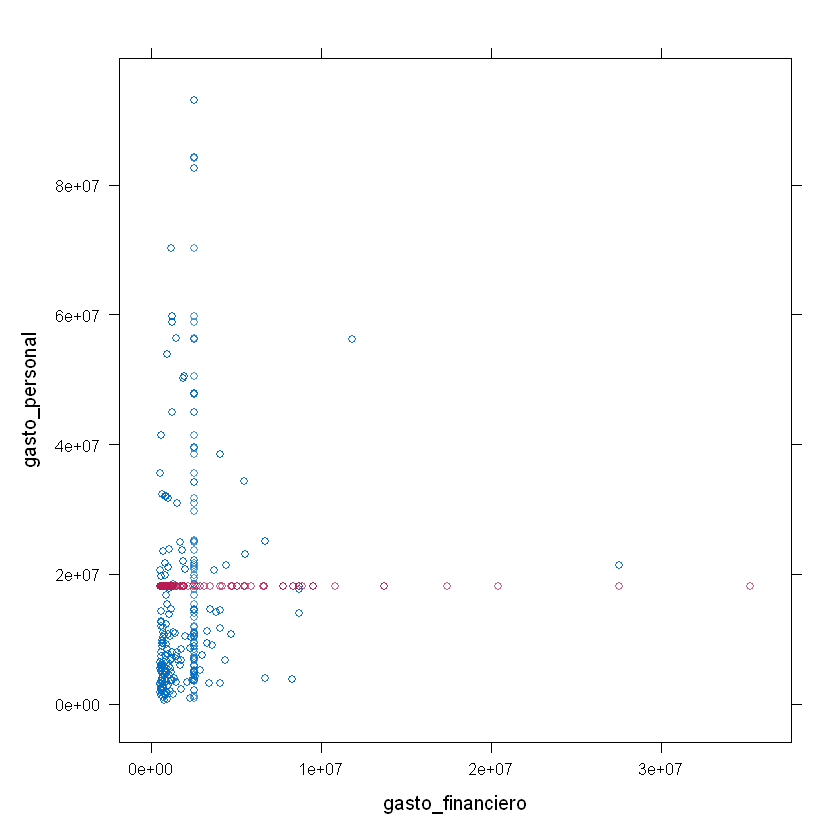
xyplot(imp_data_mean, gasto_personal ~ gasto_financiero)
Datos imputados:
Usaremos mice::complete() para combinar los datos faltantes con los
imputados, note que se crea una base de datos solo con las variables
imputadas, falta la variable ventas que no tenía datos faltantes.
complete_data_mean <- mice::complete(imp_data_mean)
print(head(complete_data_mean, 10)) # En las primeras 10 filas no hay NAs.
gasto_personal gasto_financiero
1 9352991 3240559
2 18203281 1468298
3 6668544 1547666
4 22088759 2482088
5 18203281 2861773
6 5219070 2482088
7 18203281 647945
8 4756263 630568
9 18203281 20390274
10 18203281 542136
Comparación datos faltantes con imputación:
library(ggplot2)
ggplot(data = df) +
geom_density(aes(x = gasto_personal),
color = "darkred",
fill = "darkred",
alpha = 0.2) +
geom_density(aes(x = complete_data_mean[, "gasto_personal"]),
color = "darkblue",
fill = "darkblue",
alpha = 0.2) +
labs(title = "Densidad variable Gasto Personal",
subtitle = "Antes de imputación y después de imputación",
x = "Gasto Personal",
y = "Frecuencia")
Warning message:
"Removed 113 rows containing non-finite values (stat_density)."
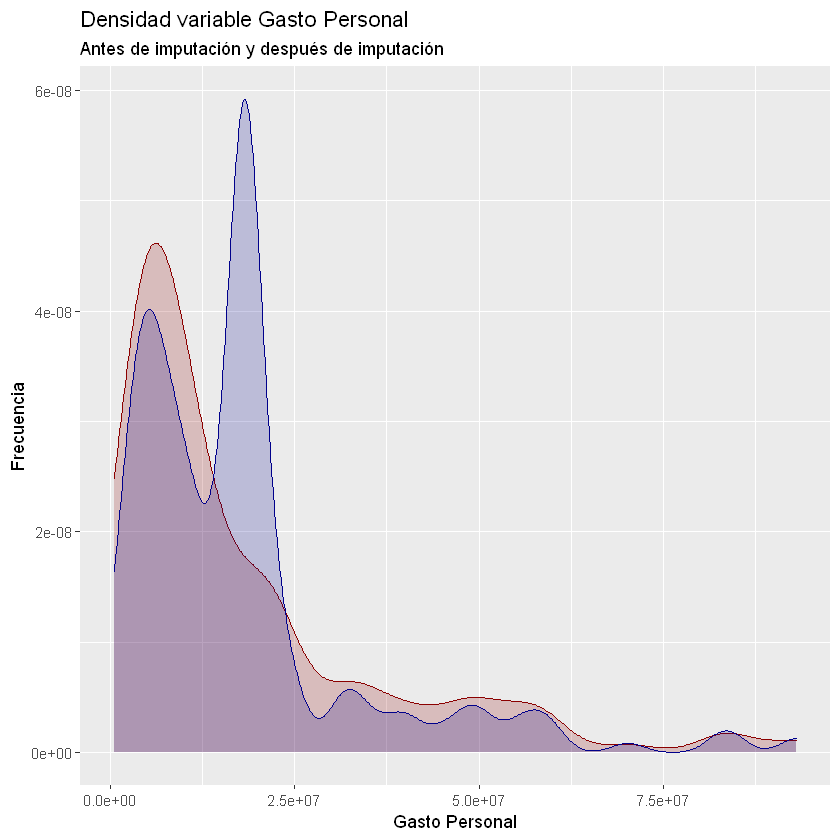
El gráfico de densidad azul es la variable con la imputación de datos, se observa que los datos se concentran más en la media.
ggplot(data = df) +
geom_density(aes(x = gasto_financiero),
color = "darkred",
fill = "darkred",
alpha = 0.2) +
geom_density(aes(x = complete_data_mean[, "gasto_financiero"]),
color = "darkblue",
fill = "darkblue",
alpha = 0.2) +
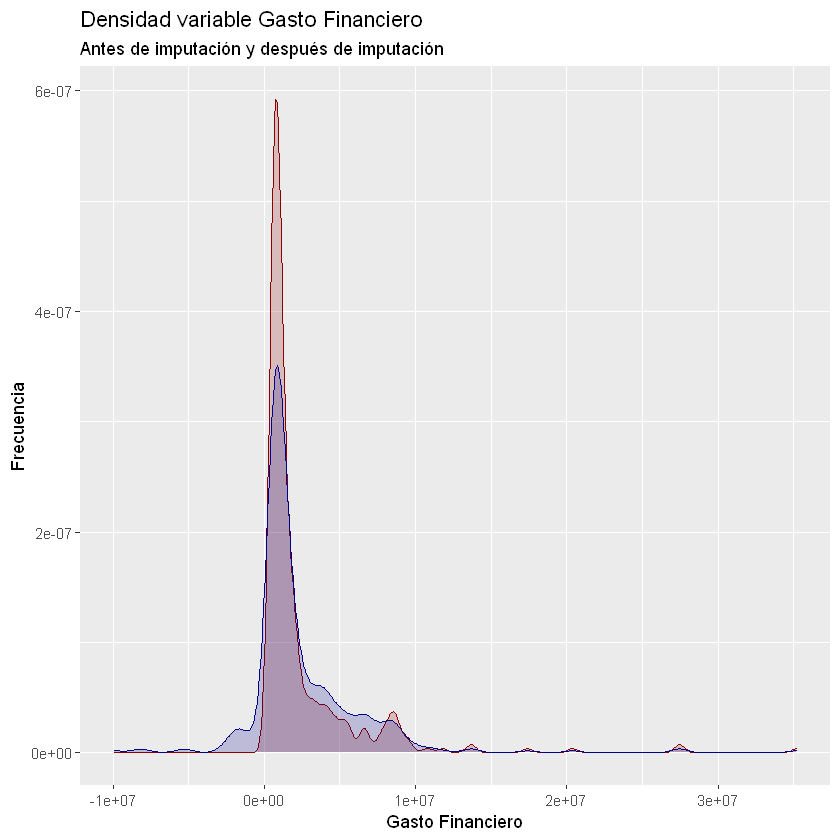
labs(title = "Densidad variable Gasto Financiero",
subtitle = "Antes de imputación y después de imputación",
x = "Gasto Financiero",
y = "Frecuencia")
Warning message:
"Removed 97 rows containing non-finite values (stat_density)."

Imputación por Regresión:
imp_data_regre <- mice(df[, c("gasto_personal", "gasto_financiero")], method = "norm.predict", m = 1, maxit = 1, print = FALSE)
complete_data_regre <- mice::complete(imp_data_regre)
xyplot(imp_data_regre, gasto_personal ~ gasto_financiero)
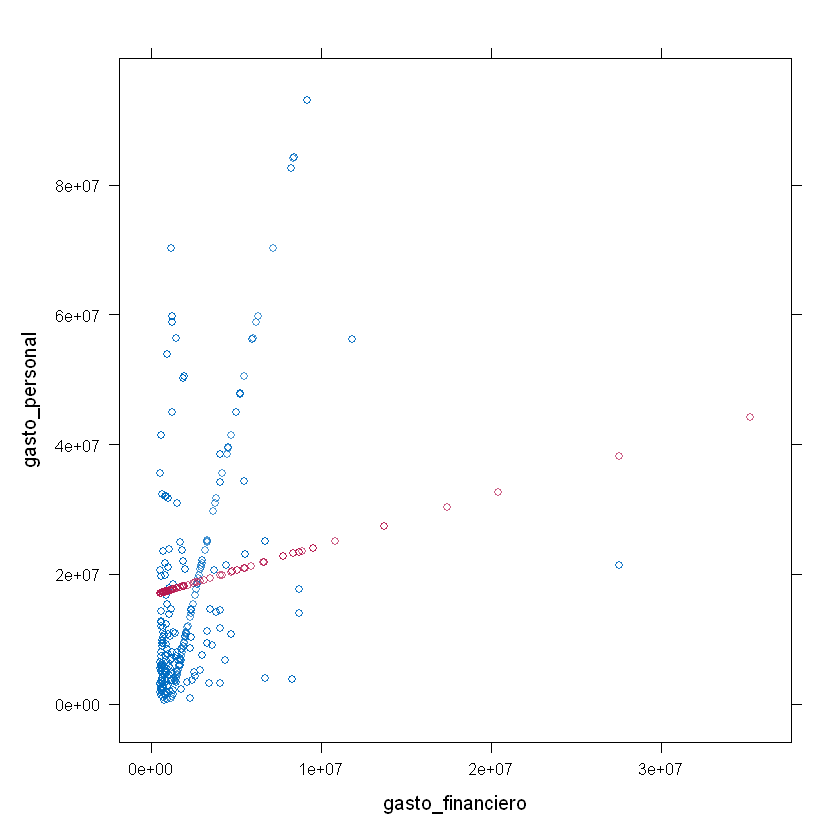
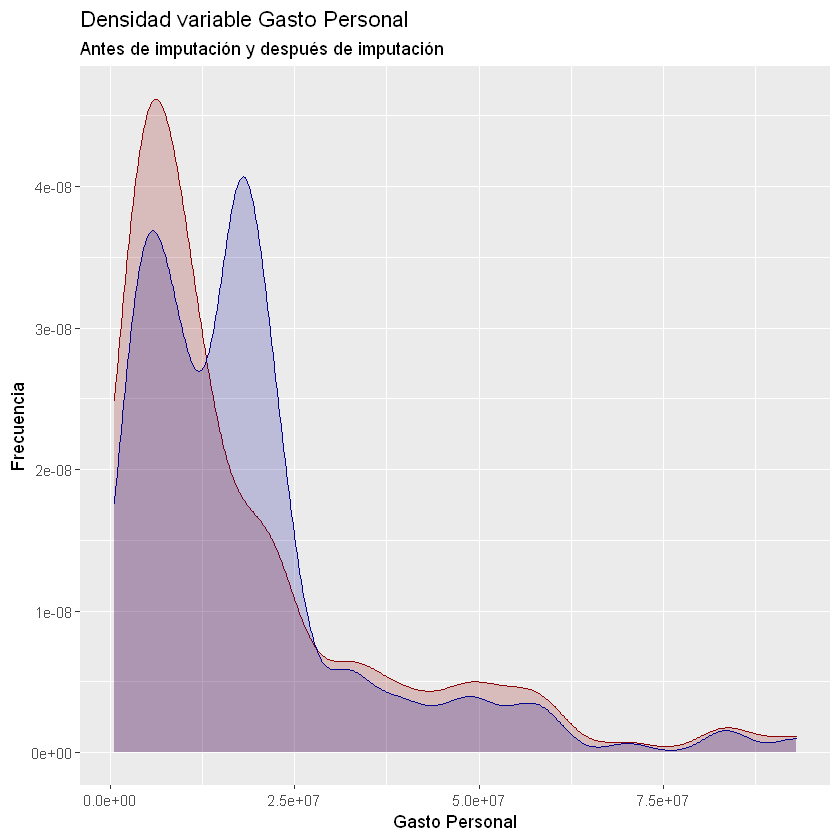
ggplot(data = df) +
geom_density(aes(x = gasto_personal),
color = "darkred",
fill = "darkred",
alpha = 0.2) +
geom_density(aes(x = complete_data_regre[, "gasto_personal"]),
color = "darkblue",
fill = "darkblue",
alpha = 0.2) +
labs(title = "Densidad variable Gasto Personal",
subtitle = "Antes de imputación y después de imputación",
x = "Gasto Personal",
y = "Frecuencia")
Warning message:
"Removed 113 rows containing non-finite values (stat_density)."
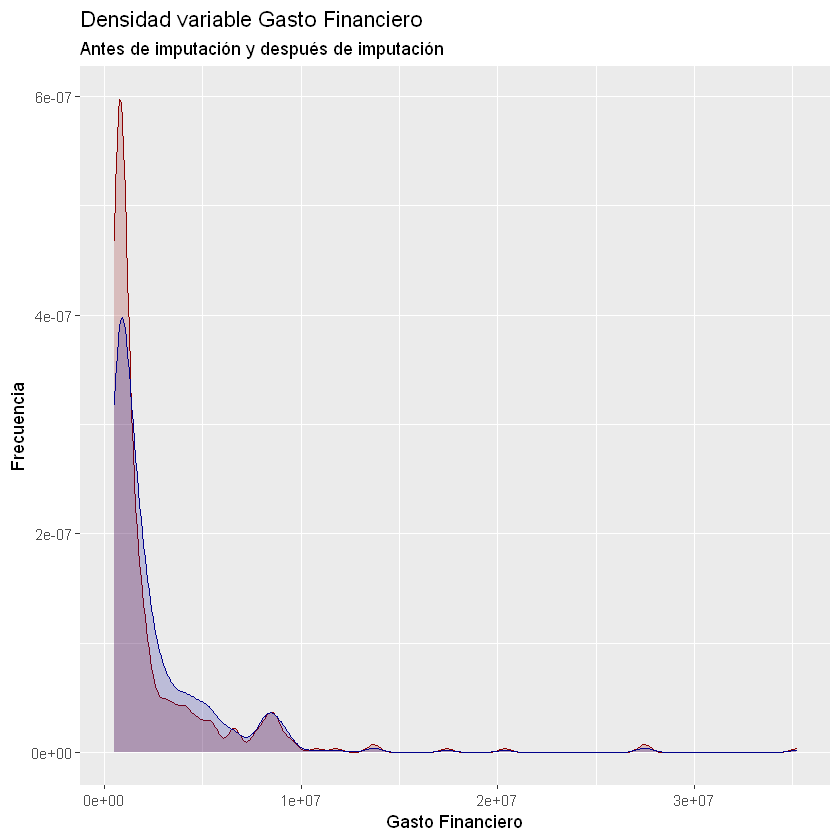
ggplot(data = df) +
geom_density(aes(x = gasto_financiero),
color = "darkred",
fill = "darkred",
alpha = 0.2) +
geom_density(aes(x = complete_data_regre[, "gasto_financiero"]),
color = "darkblue",
fill = "darkblue",
alpha = 0.2) +
labs(title = "Densidad variable Gasto Financiero",
subtitle = "Antes de imputación y después de imputación",
x = "Gasto Financiero",
y = "Frecuencia")
Warning message:
"Removed 97 rows containing non-finite values (stat_density)."
Imputación por Regresión Estocástica:
imp_data_stoch <- mice(df[, c("gasto_personal", "gasto_financiero")], method = "norm.nob", m = 1, maxit = 1, print = FALSE)
complete_data_stoch <- mice::complete(imp_data_stoch)
xyplot(imp_data_stoch, gasto_personal ~ gasto_financiero)

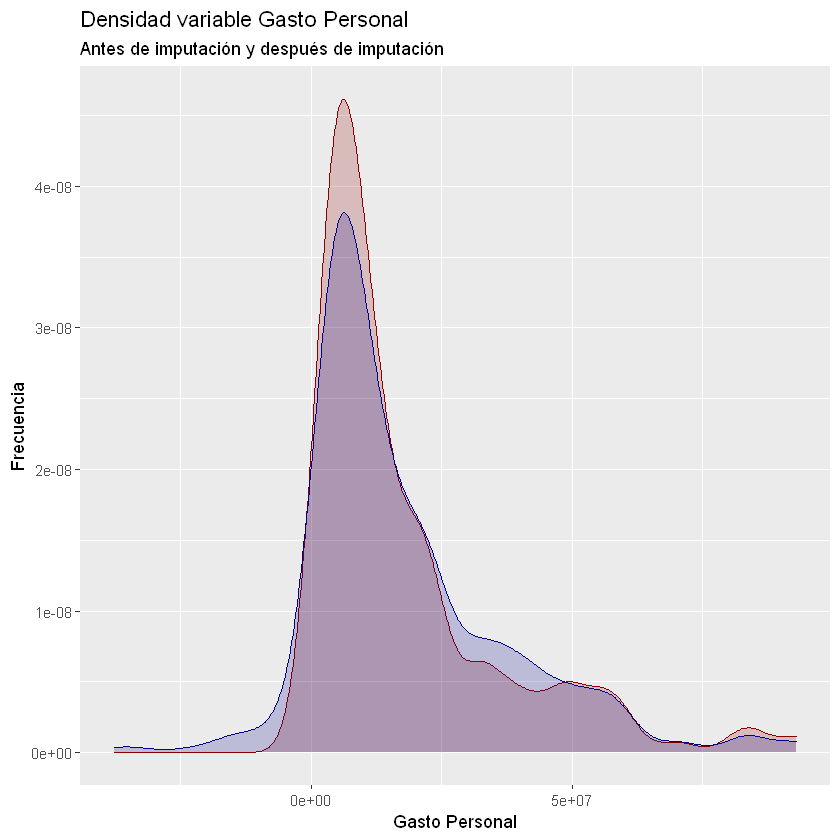
ggplot(data = df) +
geom_density(aes(x = gasto_personal),
color = "darkred",
fill = "darkred",
alpha = 0.2) +
geom_density(aes(x = complete_data_stoch[, "gasto_personal"]),
color = "darkblue",
fill = "darkblue",
alpha = 0.2) +
labs(title = "Densidad variable Gasto Personal",
subtitle = "Antes de imputación y después de imputación",
x = "Gasto Personal",
y = "Frecuencia")
Warning message:
"Removed 113 rows containing non-finite values (stat_density)."
ggplot(data = df) +
geom_density(aes(x = gasto_financiero),
color = "darkred",
fill = "darkred",
alpha = 0.2) +
geom_density(aes(x = complete_data_stoch[, "gasto_financiero"]),
color = "darkblue",
fill = "darkblue",
alpha = 0.2) +
labs(title = "Densidad variable Gasto Financiero",
subtitle = "Antes de imputación y después de imputación",
x = "Gasto Financiero",
y = "Frecuencia")
Warning message:
"Removed 97 rows containing non-finite values (stat_density)."